
The problem that started this was not philosophical. We were trying to write down our SDLC. Not the aspirational one on a Confluence page, the real one, the one an auditor could follow and a team could actually live inside. Every draft failed the same way. Make it specific enough to collect evidence against, and it boxed teams into one way of working that half of them did not use. Leave it loose enough to fit how teams actually worked, and the auditor found gaps. The document could be auditable, or it could be true. It could not be both.
It gets worse when you notice there is not one lifecycle to write down. There are at least three.
Three Lifecycles, One Soup
Three acronyms show up in these conversations, usually from three different parts of the company.
PDLC, the product development lifecycle, owns the why and the what: discovery, definition, prioritization, delivery, and learning from what shipped. SDLC, the software development lifecycle, owns the how of building: version control, review, testing, deployment, operation. AI-DLC, the newest and least settled, owns building systems that reason instead of follow instructions. It does not even have a stable name yet. AWS calls it the AI-Driven Development Life Cycle. Salesforce calls its version the Agent Development Lifecycle. IBM and others say ADLC. The thing has three names, which tells you how early it is.
The acronyms imply three separate processes. They are mostly the same process. SDLC is the engineering core that sits inside PDLC: software is one of the ways a product gets built, and the build-test-ship machinery is shared. AI-DLC shares most of that same machinery, the version control, the CI/CD, the deploy gates, and then adds a handful of stages SDLC never needed. Salesforce’s own framing is the honest one. Its closing principle is “Evolution, Not Replacement”: the agent lifecycle extends the software lifecycle, it does not start over.
So the real question is narrower than which of three processes to adopt. It is where they genuinely diverge, and what to do about everything they share.
What Halfway-Decent Looks Like for Each
Before optimizing anything, it helps to know what a good-enough version of each looks like, because most teams do not need the perfect one.
A halfway-decent PDLC is a written problem statement, an explicit decision that the problem is worth solving, a definition of done that includes a security and privacy review when the work warrants it, and a feedback loop after launch. That is the whole thing. It is not a twelve-stage stage-gate with a steering committee. The gate that matters is that there is a recorded decision to build this, with the risk review attached to it.
A halfway-decent SDLC is version control, peer review on changes, automated tests in CI, a deploy that someone or something approved, and a record of what shipped and when. The gates that matter are that the change was reviewed, the tests ran, the deploy was authorized, and there is a log. Notice what is absent from that list: a mandated branching strategy, a specific ticket workflow, a required framework. Those are steps, and steps are where teams differ.
A halfway-decent AI-DLC is everything in the SDLC baseline plus four things the deterministic world never required: an evaluation against a held-out set with a release threshold, an adversarial or guardrail test, a named human who signs off on behavior, and drift monitoring with a way to roll back. Salesforce unit-tests the deterministic tools an agent calls, the Flows and Apex, exactly like normal software, and then tests the agent’s reasoning behaviorally, because there is no single correct output to assert against.
| Lifecycle | Owns | Halfway-decent baseline | The gates that matter |
|---|---|---|---|
| PDLC | The why and the what | Problem statement, a real build/no-build decision, definition of done with a risk-review trigger, post-launch feedback | A recorded decision to build, with the risk review attached |
| SDLC | The how of building | Version control, peer review, tests in CI, an approved deploy, a record of what shipped | Change reviewed, tests passed, deploy authorized, log exists |
| AI-DLC | Building systems that reason | SDLC baseline plus eval-against-threshold, adversarial/guardrail test, human sign-off on behavior, drift monitoring with rollback | The four above, on top of the SDLC gates |
Standardize the Gates, Not the Steps
Here is the resolution to the auditable-or-true problem. What an auditor actually wants is narrow: evidence that specific things happened. The change was reviewed, the risk was assessed, the test passed, a human took responsibility. Those are gates. Everything between the gates, how a team got from one to the next, is steps, and the auditor does not care about the steps as long as the gate produced its evidence.
So you standardize the gates and you free the steps. The gate set is the contract: every team, on every lifecycle, hits the same control points and produces the same evidence shape at each one. How they move between gates is theirs. One team runs trunk-based development, another runs GitFlow. One writes tests in Jest, another in pytest. One evaluates agents with RAGAS, another with a homegrown eval suite. The gate (“tests ran and passed, here is the record”) is identical across all of them. The step (“how we test”) is autonomous.
This is the move that makes the written-down process both auditable and true. It is auditable because the gates are fixed and evidenced. It is true because it never lies about how teams work in between.
Codify the Gates So Evidence Collects Itself
A gate that relies on someone remembering to attach a screenshot will not survive a busy quarter. The version that works is codified: each gate emits a machine-readable artifact as a side effect of the work itself.
This is the same argument I made in GRC engineering and in telemetry-driven access reviews. Stop generating documents about controls and start emitting machine-readable assertions about what actually happened. A pull-request approval is evidence the change was reviewed. A green CI run is evidence the tests passed. A signed deploy record is evidence the release was authorized. An eval report with a result against a threshold is evidence the model cleared the bar. A sign-off with a name on it is evidence a human took responsibility. None of those are written for the auditor. They are produced by the work, and the auditor reads them afterward. Open-source tooling exists for each link in that chain: OSCAL expresses controls and their evidence as machine-readable data, Conftest, built on OPA, runs policy checks as a pipeline gate that emits a pass or fail, and Sigstore signs build provenance so a deploy record can prove itself. Above that open-source layer, commercial platforms aggregate the same artifacts: compliance tools like Vanta, Drata, and Anecdotes pull control evidence from your stack, and ASPM tools like Apiiro and Cycode correlate the code-to-deploy signals. They read the gates rather than replace them.
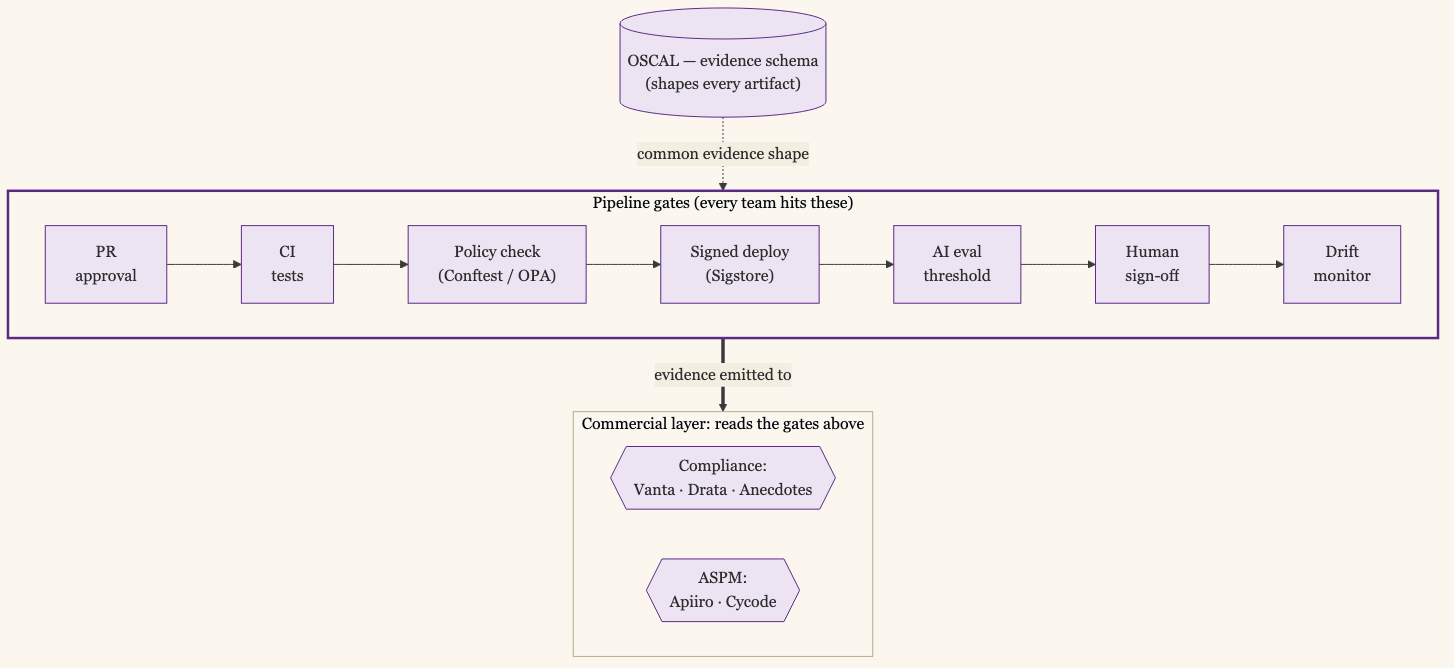
When the gates emit their own evidence, the audit stops being an event you prepare for and becomes a query you run. You are not assembling an evidence package against a calendar. You are pointing at a system that already has the answer, which is the same place compliance work itself is heading. If you want a working starter, the gate catalog and its mappings to SOC 2, ISO 27001, PCI DSS 4.0, and HIPAA are public domain — adapt them to your audit.
Where AI-DLC Earns Its Own Branch
Most of AI-DLC rides the shared spine. The genuinely new gates are few, and they are worth naming precisely, because they are the only places a separate branch is justified.
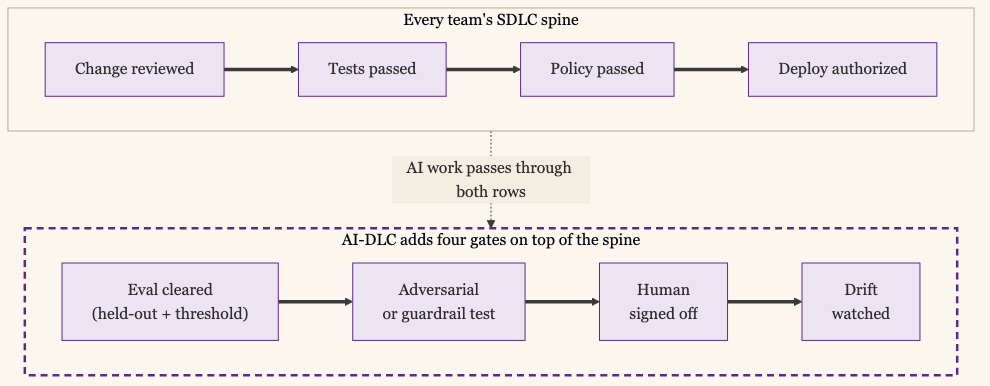
An evaluation gate exists because an agent has no single correct output, so “the tests passed” is replaced by “the behavior cleared a threshold on a representative set.” An adversarial gate exists because the input space is open and hostile in a way a typed function signature is not. A human sign-off exists because automated checks cannot score tone, helpfulness, or judgment. A drift gate exists because the system keeps changing after deploy, as data shifts and the model is tuned, which deterministic software does not do on its own.
Everything else, the version control, the CI/CD, the deploy approval, the change log, is the same gate you already had. Add the four. Do not rebuild the other twenty.
When the Spine Is the Wrong Shape
This breaks in a few specific places, and pretending it does not is how you end up with gates that produce evidence of nothing.
A research or prototyping team forced through production gates will either stop exploring or start faking the evidence. Early, throwaway work needs a much smaller gate set, and the honest move is to scope it out explicitly rather than pretend a spike went through change control.
A gate that does not fit a lifecycle becomes a checkbox. Make a content team attest to “adversarial testing” because it is on the standard list and you have taught everyone that the gates are theater. The gate set has to be the minimal set that is genuinely shared, and lifecycle-specific gates have to live on the branch, not the spine.
And evidence is not assurance. A green CI run proves a pipeline ran, not that the tests were any good. An eval that passed proves the threshold was met, not that the threshold was set correctly. Codifying the gates makes the evidence cheap and consistent, which is a real and large win, and it still does not make the underlying control effective. That part is judgment, and it does not automate away.
The Process Was Never the Point
We never did write the perfect SDLC, and I have stopped trying. What we wrote instead was a short list of gates that every team hits, with each gate emitting its own evidence, and then we got out of the way on everything between them.
The acronyms will keep multiplying. PDLC, SDLC, AI-DLC, and whatever follows agents. They will keep overlapping, and most of the overlap is real. The durable thing was never the process diagram. It is the set of control points you can prove you passed, and the room you leave teams to reach them their own way. Standardize the gates. Leave the steps alone.