
At 3am the database is down, the on-call engineer needs in, and the system that normally grants access is part of what is broken. This is the moment every “no standing access” design has to answer, and the answer is break-glass: a pre-arranged emergency path in. Get it right and it is a controlled exception that auditors respect. Get it wrong and it is a standing backdoor with a dramatic name.
What Makes It Break-Glass and Not a Backdoor
Emergency access has to exist. What makes it break-glass instead of a backdoor is everything around it.
Inert until used. The credential exists but grants nothing in normal operation, or sits behind a seal that has to be deliberately broken. Using it is a discrete, visible act, not a quiet login.
Loud. Breaking the glass fires an alarm: a page to the security team, an incident record, a notification nobody can miss. The design assumes use is rare and every use is examined. A backdoor is quiet. Break-glass is the opposite, by construction.
Time-boxed and auto-expiring. The access lasts for the incident, not forever. It grants elevated rights for a bounded window and revokes itself, so a 3am emergency does not become a permanent grant nobody remembered to remove.
Reviewed after, every time. Because use is rare and alarmed, every break-glass event gets a look: was it justified, what was done, should anything change. The review is what keeps the path honest.
Inert, loud, time-boxed, reviewed. That list is the whole difference between an emergency exit and a hole in the wall.
The Anti-Patterns
Two failures turn break-glass back into a backdoor.
The standing “just in case” admin. Someone decides on-call needs permanent elevated access so they are never stuck in an emergency. Now the emergency access is always on, used routinely, and indistinguishable from normal access. The convenience of never having to break the glass is exactly what makes it a backdoor.
The shared break-glass credential nobody rotates. A root password in a vault that five people know, used occasionally, never rotated, never attributed. When it is used you cannot say who used it, and when one of the five leaves, the credential walks out with them. Shared and static is how a break-glass account becomes the least-governed, highest-privilege thing you own.
Make It Hard Enough, but Not Too Hard
The real tension is friction. A break-glass path that is too easy gets used routinely and decays into standing access. A break-glass path that is too hard gets bypassed: when the glass is so painful to break that engineers cut a side door “just for now,” you have lost both the control and the audit trail.
The calibration is that breaking the glass should be fast enough to use under real pressure and costly enough in attention that nobody reaches for it when the normal path would do. Fast to execute, expensive to ignore: it pages people, it creates a record, someone will ask about it tomorrow. That asymmetry, easy to do and impossible to hide, is what keeps it an exception instead of a habit.
The Broker Makes This Easier
If you already run an authorization broker, break-glass is a policy on it rather than a separate system: a high-privilege grant that requires an incident, pages on use, expires fast, and records the session like any other access. The broker gives you inert-until-used, loud, time-boxed, and reviewed for free, because those are the properties it already provides for normal access. Break-glass done well is mostly the broker’s strictest policy, not a parallel mechanism with its own rules and its own rot.
When the Broker Is What’s Down
The catch is that a broker is a system too, and the worst outages take it with them. If break-glass is only a policy on the broker, the one failure it cannot survive is the broker’s own. The scenario at the top of this post, where the thing that normally grants access is part of what is broken, is exactly that case, and a broker-only break-glass walks straight into it.
So a real plan has two tiers. The first is broker-mediated and handles almost everything: a database is down, an app is wedged, a dependency failed, but the identity plane is healthy, so you break the glass through the broker and get inert, logged, time-boxed access. The second is the last resort for when the identity plane itself is down, the broker, the SSO, the credential issuer, and it cannot lean on any of them.
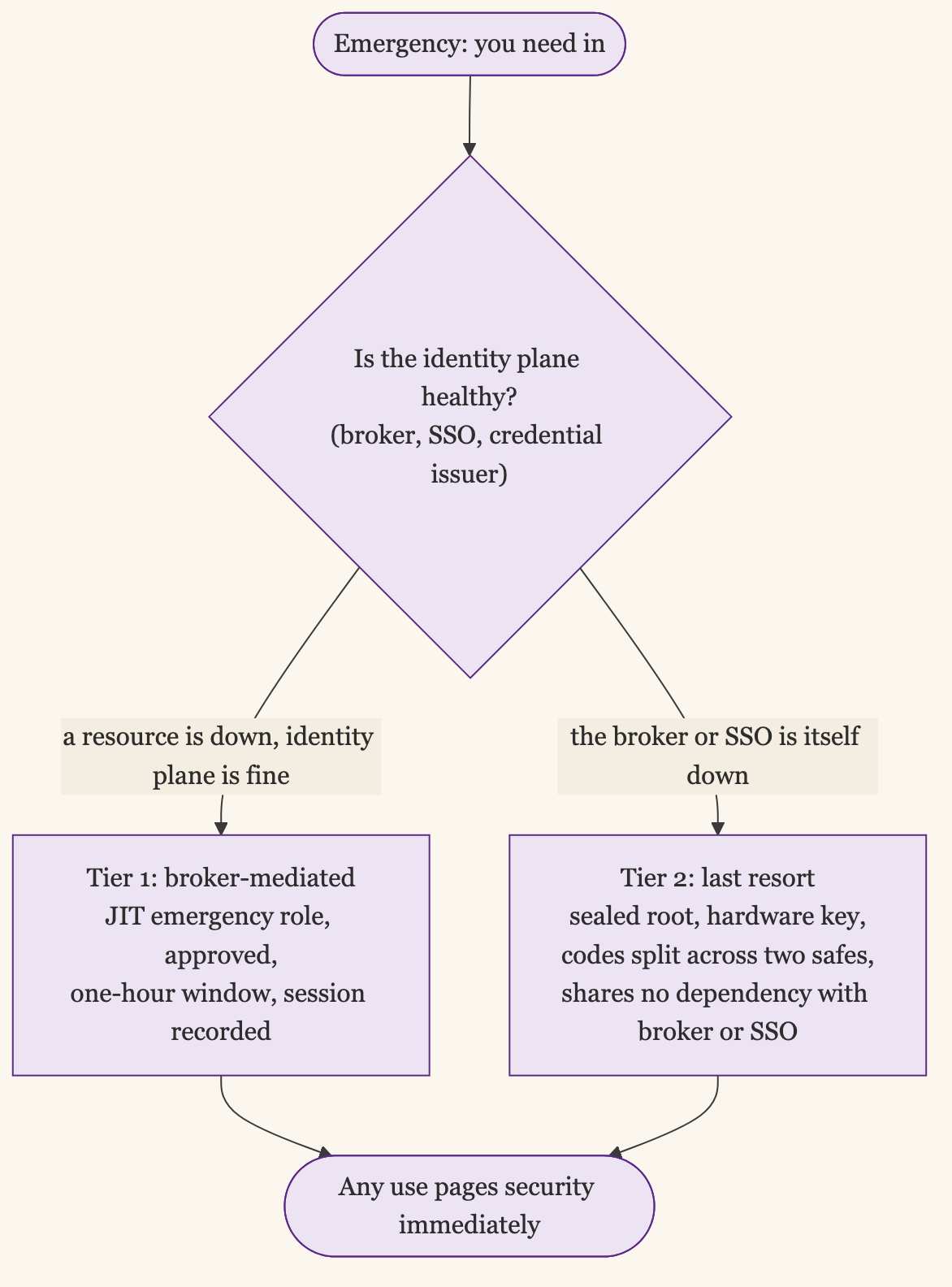
The principle that makes the second tier work is dependency independence: a break-glass path must not depend on the system it exists to recover. If the broker authenticates through your IdP, the broker’s own break-glass cannot also go through that IdP, because the IdP is a thing that can be down. The last-resort path is usually deliberately low-tech: a cloud root credential with a hardware key in a safe, a local console password in a sealed envelope, an out-of-band management network that does not route through the same control plane. It is slower, more manual, and more painful, and that is acceptable, because it is the path you take maybe once a year when everything else is on fire.
What it cannot skip is the discipline. The last-resort credential is still inert until used, still alarmed on a channel that does not depend on what is down, still attributed through the process around it, and still reviewed hard afterward, often with two people required to open the safe so the attribution is built into the act. The compensating controls move from the system to the procedure, but they do not disappear. A sealed root credential with a two-person rule and a mandatory postmortem is break-glass. The same credential in a shared vault is the anti-pattern from earlier with a better story.
What It Actually Looks Like
On a cloud platform, both tiers are recognizable builds.
Inert-until-used is enforced with a guardrail, not a promise. On AWS, a service control policy denies the most dangerous actions for every principal in the account, and the break-glass role is the single principal the policy exempts. Day to day nobody can take those actions, including an over-privileged account, because the policy blocks them. Breaking the glass means assuming the one role the guardrail lets through, which is a discrete, logged act instead of a quiet escalation.
The policy is short. It denies the actions an attacker would use to disable your safety controls, and exempts exactly one role:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DenyGuardrailTamperingExceptBreakGlass",
"Effect": "Deny",
"Action": [
"cloudtrail:StopLogging",
"cloudtrail:DeleteTrail",
"config:DeleteConfigurationRecorder",
"guardduty:DeleteDetector",
"kms:ScheduleKeyDeletion",
"iam:DeleteRolePermissionsBoundary",
"organizations:LeaveOrganization"
],
"Resource": "*",
"Condition": {
"ArnNotLike": {
"aws:PrincipalArn": "arn:aws:iam::*:role/BreakGlassEmergency"
}
}
}
]
}
The ArnNotLike condition is the whole mechanism: every principal in the account is denied these actions except the one role whose ARN matches, and that role is assigned to nobody until the glass is broken. An SCP only sets the ceiling, so the break-glass role still needs its own permissions policy granting these actions; the SCP’s job is to stop everyone else from having them. Azure and GCP have the same shape with organization policies and a privileged emergency role.
Tier one, the broker-mediated path, is a just-in-time elevation. The emergency role exists but is assigned to nobody. In an incident the on-call requests it through Azure PIM, an AWS IAM Identity Center permission set, or the broker’s emergency policy; an approval fires, or for a genuine page-out emergency a justification plus a mandatory after-the-fact review; the role activates for a bounded window like one hour; the session is recorded; and it expires on its own. This is the right path for almost every incident, because in almost every incident the identity plane is fine. If you would rather not build tier one yourself, the just-in-time PAM tools do exactly this: StrongDM, Teleport, Apono, and BeyondTrust all broker time-boxed access, gate it behind approval or justification, page on use, and record the session. They cover the broker-mediated tier. Tier two is the part no vendor can hold for you.
Tier two, the last resort, is the account that can rebuild the identity plane: the AWS Organizations management account root, the Azure global administrator emergency account, the GCP super admin. It gets a hardware security key, and the password or recovery codes are split so no single person can use it alone, stored offline in two separate safes. Its sign-in alarms to a monitoring path that does not run through your normal SSO or your normal cloud account, because those are the things that may be down. You touch it with two people, you write the postmortem, and most years you never touch it at all.
The alarm is the through-line. Any authentication as any break-glass identity, tier one or tier two, pages the security team immediately, because a break-glass account used without an alarm is just a privileged account nobody is watching.
An Exit, Not an Opening
Every system needs a way in when the normal way is down. The question is whether that way is an emergency exit, used rarely, loudly, and briefly, or an opening someone forgot to close. The mechanics are the same either way. The difference is the discipline around them: inert until used, loud when used, gone shortly after, and reviewed every single time. Build the exit. Do not leave an opening.